Thread기본 사용 방법
C++ 11부터 Thread가 기본 라이브러리로 C++에 생성되었다.
사용하기 위해서는 #include <thread>를 명시한다.
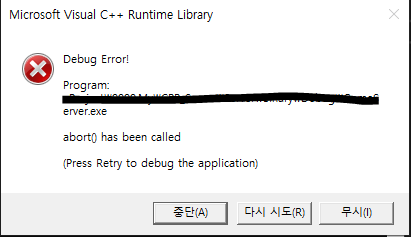
아래의 코드를 실행하면 오류가 발생한다. 오류가 발생하는 이유는 HelloThread함수가 끝나기 전에 Main thread가 종료되어 발생하는 문제이다. 이를 Join을 통해 해결할 수 있다.
#include "pch.h"
#include <iostream>
#include <thread>
void HelloThread() {
cout << "Hello Thread" << endl;
}
int main()
{
std::thread t(HelloThread);
cout << "Hello Main" << endl;
}
Join을 사용하면 새롭게 만든 t thread가 종료될 때까지 Main thread가 기다렸다가 다시 실행되기 때문에 오류가 발생되지 않는다.
void HelloThread() {
cout << "Hello Thread" << endl;
}
int main()
{
std::thread t(HelloThread);
cout << "Hello Main" << endl;
t.join();
}
thread 기능
joinable - 연동된 thread가 있는지 확인한다. 즉 지금 실행되고 있는 스레드가 있는지
join - thread가 작업을 완료할 때까지 main thread를 기다리게 한다.
hardware_concurrency - CPU 코어 개수(논리적으로 실행할 수 있는 개수)
get_id - Thread ID를 알려준다.
detach - 백그라운드 thread로 변경해 준다. 즉 Main의 스레드와 분리되며 Main thread안에서 해당 thread의 정보를 추출할 수없다.
void HelloThread() {
cout << "Hello Thread" << endl;
}
int main()
{
std::thread t(HelloThread);
cout << "Hello Main" << endl;
int32 count = t.hardware_concurrency();// CPU 코어 개수(논리적으로 실행할 수 있는 개수)
auto id = t.get_id();// Thread id
t.detach();// 백그라운드 thread로 변경해준다. 즉 Main의 쓰레드와 분리되며 Main thread안에서 해당 thread의 정보를 추출할 수없다.
t.joinable();// 연동된 thread가 있는지 확인한다.
t.join();//t thread가 작업을 완료할 때 까지 main thread를 기다리게 한다.
}
Thread와 병렬 처리와 공유자원
아래와 같은 코드를 실행한다면 결괏값이 0이 아닌 실행할 때마다 다른 결과물이 나오게 된다.
int32 sum은 전역변수이기 때문에 데이터영역에 할당되며 이를 병렬로 처리할 경우 두 Thread가 같은 값을 본 상태에서 읽고 각각 실행한다고 해도 어셈블리는 int32 eax = sum; -> eax = eax + 1 -> sum = eax; 이렇게 3번으로 나누어서 결과 적으로는 변수에 값을 덮어쓰는 방식으로 실행된다. 그래서 같은 값을 가지고 동시에 실행했다고 해도 간발에 차이로 뒤늦게 공유자원을 종료한 thread의 값이 덮어 쓰여서 다른 값이 나오게 된다.
이런 문제를 해결하기 위해서는 동기화하는 방법이 필요하다.
int32 sum = 0;
void Add() {
for (int32 i = 0; i < 100'0000; i++)
{
sum++;
}
}
void Sub() {
for (int32 i = 0; i < 100'0000; i++)
{
sum--;
}
}
int main()
{
Add();
Sub();
std::thread t1(Add);
std::thread t2(Sub);
t1.join();
t2.join();
cout << sum << endl;
}
공유자원과 Atomic(원자적 접근)
이런 문제를 해결하기 위해 atomic이란 문법이 있다.
atomic이란 ALL OR Nothing이란 뜻으로 즉 전부실행 하거나 하나도 실행하지 않게 하는 방법이다. DB에 존재하는 트렌젝션의 개념과 유사하다.
누가 먼저 하는지에 대해서는 cpu가 결정하며 병목현상이 일어날 수 있어 속도상으로는 상당히 느리기 때문에 반드시 필요하지 않다면 자주 사용하는 건 좋지 않다.
atomic을 사용했다고 해서 반드시 원자적으로 접근한다는 건 아니다. cpu 비트인지에 따라 원자적으로 처리할 수 있는 형식이 다르다 64비트라면 int64만을 원자적으로 처리할 수 있다. 즉 다양한 필드가 들어있는 class를 atomic키워드로 감싼다고 해서 원자성을 보존하지는 않고 lock을 걸어줘야 한다.
#include <atomic>
//atomic : All-or-Nothing(전부실행 하거나 하나도 실행하지 않게) db의 트렌젝션 개념
atomic<int32> sum = 0;
void Add() {
for (int32 i = 0; i < 100'0000; i++)
{
sum.fetch_add(1);
//sum++;
}
}
void Sub() {
for (int32 i = 0; i < 100'0000; i++)
{
sum.fetch_add(-1);
//sum--;
}
}
int main()
{
Add();
Sub();
std::thread t1(Add);
std::thread t2(Sub);
t1.join();
t2.join();
cout << sum << endl;
}Atomic과 Memory Model
일반적으로 우리가 개발한 소스코드는 cpu나 컴파일에 의해서 최적화된다.
Memory Model 정책
1. Sequentially Consistent (seq_cst)
2. Acquire-Release (acquire, release)
3. Relaxed (relaxed)
1. seq_cst
- 가장엄격하며 컴파일러 최적화 여지가 적다. (가시성과 코드 재배치 문제가 일어나지 않는다.)
2. acquire-release
- release 명령 이전의 메모리 명령들이 해당 명령 이후로 재배치되는 것을 금지한다.
- release 이전의 명령들이 acquire 하는 순간에 관찰된다.(가시성 보장)
3. relaxed - 자유도가 높아 컴파일러 최적화의 여지가 많아 직관적이지 않다.
- 순서 일관성(Memory Ordering):
- C++ 메모리 모델은 연산의 순서와 메모리 접근의 순서를 명시적으로 제어합니다. 이를 통해 멀티스레드 환경에서의 메모리 접근을 조정하고 동기화할 수 있습니다.
- std::memory_order 열거형을 통해 순서 일관성을 지정할 수 있습니다. 예를 들어, std::memory_order_acquire, std::memory_order_release, std::memory_order_seq_cst 등이 있습니다.
- 원자적 연산(Atomic Operations):
- 원자적 연산은 한 번에 완전히 실행되거나 전혀 실행되지 않는 연산을 말합니다.
- std::atomic 템플릿 클래스를 사용하여 원자적 연산을 수행할 수 있습니다. 이를 통해 메모리에서의 데이터 경쟁을 방지하고 스레드 간 데이터 공유를 안전하게 관리할 수 있습니다.
- 스레드 지역 저장(Thread-Local Storage):
- C++11 이후부터 thread_local 키워드를 사용하여 스레드 지역 변수를 정의할 수 있습니다. 스레드 지역 변수는 각 스레드마다 독립적으로 유지되며 다른 스레드에 영향을 미치지 않습니다.
- 동기화(Synchronization):
- C++ 메모리 모델은 다양한 동기화 메커니즘을 제공합니다. 예를 들어, 뮤텍스, 세마포어, 조건 변수 등을 사용하여 스레드 간 동기화를 수행할 수 있습니다.
std::atomic<bool> atomicBool;
atomicBool.store(true, memory_order::memory_order_seq_cst); // 변수에 10을 저장
while(atomicBool.load(memory_order::memory_order_seq_cst) == false)
;멀티 Thread와 STL(Standard Template Library) Container
c++에서 사용하는 STL(Standard Template Library) Container은 기본적으로 멀티스레드 환경에서 동작하지 않는다.
Container의 vector로 예를 들어보면 멀티스레드 환경에서 아래와 같이 실행한다면 오류가 발생하게 되며 이 오류는 Double free 오류이다. vector 같은 경우 데이터가 꽉 차면 해당 데이터 영역을 지우고 다시 더 크게 메모리를 할당한다. 이때 서로 다른 스레드가 우연하게 같은 메모리를 지울 때 double free오류가 발생한다.
vector<int32> v;
void push() {
for (int32 i = 0; i < 10000; i++)
{
v.push_back(i);
}
}
int main()
{
std::thread t1(push);
std::thread t2(push);
t1.join();
t2.join();
cout << v.size() << endl;
}크리티컬섹션
C++에서 '크리티컬 섹션(Critical Section)'은 멀티스레드 프로그래밍에서 동기화를 위해 사용되는 중요한 개념입니다. 크리티컬 섹션은 여러 스레드가 동시에 접근해서는 안 되는 공유 자원을 안전하게 보호하기 위한 코드 영역을 의미합니다.
일반적으로 크리티컬 섹션은 공유 데이터나 리소스에 대한 접근을 동기화하기 위해 사용됩니다. 여러 스레드가 동시에 이러한 데이터나 리소스에 접근하면 충돌이 발생하여 예상하지 못한 동작이 일어날 수 있습니다. 크리티컬 섹션은 이를 방지하기 위해 특정 코드 영역을 한 번에 하나의 스레드만 접근할 수 있도록 보호합니다.
C++에서 크리티컬 섹션을 구현하기 위해 다양한 방법이 있습니다. 가장 일반적인 방법 중 하나는 C++11부터 제공되는 std::mutex 클래스를 사용하는 것입니다. std::mutex는 뮤텍스(mutex)라는 동기화 메커니즘을 제공하여 크리티컬 섹션을 보호합니다. 뮤텍스를 사용하여 특정 코드 영역을 잠그고(unlock) 잠금(lock)을 해제함으로써 여러 스레드 간에 안전하게 공유 자원에 접근할 수 있습니다.
또한, C++에서는 std::lock_guard와 같은 RAII(Resource Acquisition Is Initialization) 기반의 클래스들도 널리 사용됩니다. std::lock_guard는 뮤텍스 락을 자동으로 잠그고 해제하여 스코프 벗어나는 경우 자동으로 락을 해제하여 코드의 안전성을 유지합니다.
요약하면, 크리티컬 섹션은 멀티스레드 환경에서 공유 자원에 대한 안전한 접근을 보장하기 위한 동기화 메커니즘으로, C++에서는 뮤텍스와 RAII를 활용하여 구현하는 경우가 많습니다.
mutex와 공유자원(상호배타적 접근)
mutex c++에서 lock을 거는 방법이다.
mutex는 멀티스레드 환경에서 순차적으로 스레드가 공유자원을 사용할 수 있게 보장해 준다.(상호배타적)
한 번에 한 스레드만 지나갈 수 있기 때문에(결국에는 싱글스레드 효과) 너무 많은 경합이 일어날 수 있어 무거운 작업에서는 그만큼 딜레이가 생긴다는 문제가 있다.
또 한 mutex는 재귀적으로 lock을 걸 수 없다. 즉 lock이 후 lock이 불가능하다.
그리고 lock을 한 후 unlock을 하지 않으면 뒤에 thread들은 lock이 풀리지 않아 영원히 기다려야 할 수밖에 없다. 이런 문제를 해결하기 위해 RAII(Resource Acqisition is Initialization) 패턴이 존재한다.
#include<thread>
#include <mutex>
vector<int32> v;
mutex m;
void push() {
m.lock();
for (int32 i = 0; i < 10000; i++)
{
v.push_back(i);
}
m.unlock();
}
int main()
{
std::thread t1(push);
std::thread t2(push);
t1.join();
t2.join();
cout << v.size() << endl;
}LockGuard와 RAII(Resource Acqisition is Initialization) 패턴
RAII는 "Resource Acquisition Is Initialization"의 약자로, C++에서 자원 관리를 위한 중요한 디자인 패턴 중 하나입니다. 이 패턴은 자원의 할당과 해제를 객체의 생성과 소멸에 의존시킴으로써 자원 누수를 방지하고 예외 처리를 간소화하는 데 사용됩니다.
이 패턴의 핵심 아이디어는 다음과 같습니다.
자원 할당 초기화 - 객체가 생성될 때 자원을 할당하고, 이 객체가 스코프를 벗어나면 자원이 자동으로 해제되도록 합니다.
소멸자를 활용한 자원 해제 - C++의 소멸자(destructor)를 이용하여 자원을 안전하게 해제합니다. 객체가 파괴될 때 자원을 자동으로 해제하므로 개발자가 명시적으로 자원을 해제할 필요가 없습니다.
이 패턴은 주로 리소스 관리에 중점을 두는 작업에서 사용됩니다. 예를 들어, 파일 핸들, 메모리 할당, 락(lock) 등의 자원을 효과적으로 관리할 수 있습니다.
아래는 직접 만든 LockGuard지만 기본 템플릿에도 lock_guard라는 명으로 제공해 준다.
vector<int32> v;
mutex m;
template<typename T>
class LockGuard
{
public:
LockGuard(T& m) {
_mutex = &m;
_mutex->lock();
}
~LockGuard() {
_mutex->unlock();
}
private:
T* _mutex;
};
void push() {
for (int32 i = 0; i < 10000; i++)
{
LockGuard<std::mutex> lockGuard(m);
v.push_back(i);
}
}
int main()
{
std::thread t1(push);
std::thread t2(push);
t1.join();
t2.join();
cout << v.size() << endl;
}락 구현 세 가지 방법
락구현한다는 것은 배타적인 접근한다는 뜻이다.
스레드 간의 동기화를 위해 락(lock)을 구현하는 방법으로는 여러 가지가 있습니다. 그중에서도 주로 사용되는 방법 중 세 가지는 스핀락(Spinlock), 슬립락(Sleeplock), 이벤트 락(Event Lock)입니다.
1. 스핀락 (Spinlock):
동작 방식: 스핀락은 기다리는 동안 대기하지 않고, 자원을 얻을 때까지 반복적으로 체크하는 방식입니다. 다른 스레드가 락을 해제할 때까지 계속해서 체크를 반복합니다.(콘텍스트 스위칭이 일어나지 않는다. )
특징: 대기할 때 CPU를 계속 사용하므로 무한 루프에 빠질 위험이 있으며, 데드락에 빠질 수 있는 가능성이 있습니다. 일반적으로 짧은 임계 영역에서 효과적이며, 대기 시간이 짧을 경우 유용합니다.
2. 슬립락 (Sleeplock):
동작 방식: 슬립락은 락을 획득할 수 없는 경우, 일정 시간 동안 대기한 후에 스레드를 슬립 상태로 전환합니다. 다른 스레드가 락을 해제하면 깨어나서 다시 락을 시도합니다.
특징: 스핀락보다는 대기 시간 동안 CPU를 덜 사용하며, 대기 시간이 길 경우에 유용합니다. 하지만 스레드를 슬립 상태로 변경하고 깨우는 오버헤드가 발생할 수 있습니다.
3. 이벤트 락 (Event Lock):
동작 방식: 이벤트 락은 스레드가 락을 획득할 수 없을 때 대기하는 방식입니다. 대기하는 스레드는 이벤트 혹은 시그널을 기다리며, 락을 해제하는 스레드가 이벤트를 발생시켜 대기 중인 스레드를 깨웁니다.
특징: 슬립락과 유사하지만, 슬립 대기가 아니라 이벤트 혹은 시그널을 기다리므로 슬립 락보다는 더 높은 효율을 가질 수 있습니다. 하지만 시스템에 따라 이벤트 발생에 대한 오버헤드가 발생할 수 있습니다.
이러한 락의 선택은 상황과 요구사항에 따라 다릅니다. 예를 들어, 임계 구역(critical section)이 짧을 경우에는 스핀락이 효율적일 수 있고, 대기 시간이 길 경우에는 슬립락이나 이벤트 락이 유용할 수 있습니다. 또한 데드락과 같은 문제를 피하기 위해서도 주의 깊게 선택해야 합니다.
콘텍스트 스위칭 (Context Switching)
콘텍스트 스위칭(Context Switching)'은 컴퓨터 과학과 운영 체제에서 중요한 개념입니다. 이는 CPU가 한 프로세스나 스레드에서 다른 프로세스나 스레드로 전환하는 것을 의미합니다.
모든 프로세스와 스레드는 실행에 필요한 정보들을 가지고 있습니다. 이 정보들은 CPU 레지스터의 상태, 프로세스 주소 공간, 스레드 스택 등이 포함됩니다. 하나의 프로세스나 스레드가 실행되다가 다른 프로세스나 스레드로 전환되는 경우, 현재 실행 중인 프로세스 또는 스레드의 상태 정보를 저장하고, 대기 중이던 다른 프로세스나 스레드의 상태 정보를 불러와서 실행을 재개하는 과정을 말합니다.
컨텍스트 스위칭은 여러 가지 상황에서 발생할 수 있습니다:
- 다중 프로세스 환경에서의 컨텍스트 스위칭: 운영 체제는 CPU 시간을 여러 프로세스에 분배하여 실행합니다. 한 프로세스가 I/O 작업을 기다리거나 실행이 완료되기를 기다리는 동안, CPU는 다른 프로세스를 실행할 수 있습니다. 이때 CPU는 현재 실행 중인 프로세스의 상태를 저장하고 다른 프로세스의 상태로 전환하여 실행합니다.
- 멀티스레딩 환경에서의 컨텍스트 스위칭: 하나의 프로세스 내에서 여러 스레드가 실행되는 경우, CPU는 각 스레드 간에도 전환을 수행합니다. 스레드 간의 컨텍스트 스위칭은 해당 스레드의 실행 상태를 저장하고 다른 스레드로 전환하여 실행하는 것을 의미합니다.
컨텍스트 스위칭은 시스템 성능에 영향을 미칠 수 있습니다. 상태 정보를 저장하고 불러오는 과정은 오버헤드를 발생시킬 수 있으며, 빈번한 컨텍스트 스위칭은 시스템의 처리량과 성능을 저하시킬 수 있습니다.
스핀락을 사용하여 콘텍스트 스위칭을 일으키지 않게 구조를 만들었어도 해당구역에 로그를 남기기 위해 cout<< " " <<endl를 사용한다면 이때 운영체제에게 명령을 내려 커널까지 가야해서 콘텍스트 스위칭이 일어나게 되어 오버헤드가 생겨 성능에 악영향을 줄 수 있다.
스핀락 (Spinlock) 구현
동작 방식: 스핀락은 기다리는 동안 대기하지 않고, 자원을 얻을 때까지 반복적으로 체크하는 방식입니다. 다른 스레드가 락을 해제할 때까지 계속해서 체크를 반복합니다.(콘텍스트 스위칭이 일어나지 않는다. )
특징: 대기할 때 CPU를 계속 사용하므로 무한 루프에 빠질 위험이 있으며, 데드락에 빠질 수 있는 가능성이 있습니다. 일반적으로 짧은 임계 영역에서 효과적이며, 대기 시간이 짧을 경우 유용합니다.
콘텍스트 스위칭이 일어나지 않는다. 즉 유저단에서만 움직이고 커널단까지 가지 않는다. 병합이 일어날 경우 cpu를 많이 소비한다.
#include <thread>
#include <mutex>
class SpinLock {
public:
void lock()
{
//CAS (compare-and-swap)
bool expected = false;
bool desired = true;
//compare_exchange_strong 구현부
//if (_locked == expected)
//{
// expected = _locked;
// _locked = desired;
// return true;
//}
//else
//{
// expected = _locked;
// return false;
//}
//while(_locked)
//{}
while (_locked.compare_exchange_strong(expected, desired) == false)
{
expected = false;
}
}
void unlock()
{
_locked.store(false);
}
private:
atomic<bool> _locked = false;
};
int32 sum = 0;
mutex m;
SpinLock spinLock;
void Add() {
for (int32 i = 0; i < 10'0000; i++)
{
lock_guard<SpinLock> gard(spinLock);
sum++;
}
}
void Sub() {
for (int32 i = 0; i < 10'0000; i++)
{
lock_guard<SpinLock> gard(spinLock);
sum--;
}
}
int main()
{
std::thread t1(Add);
std::thread t2(Sub);
t1.join();
t2.join();
cout << sum << endl;
}CAS (compare-And-Swap)의 compare_exchange_strong와 compare_exchange_weak
compare_exchange_strong과 compare_exchange_weak는 C++ 표준 라이브러리의 std::atomic 클래스에서 제공되는 두 가지 비교 및 교환(Compare and Swap) 메서드입니다. 이러한 메서드들은 다중 스레드 환경에서 원자적인(atomic) 연산을 수행하기 위해 사용됩니다.
- compare_exchange_strong
- std::atomic 클래스의 멤버 함수로, 해당 atomic 변수의 값을 주어진 값과 비교한 후, 값이 같으면 새로운 값을 저장하는 연산을 수행합니다.
- 이 메서드는 주어진 조건이 충족되어 값을 교환할 수 있는 경우에만 교환을 시도하고, 성공 여부를 true 또는 false로 반환합니다. 즉, 교환에 성공하면 true를 반환하고, 그렇지 않으면 false를 반환합니다.
- compare_exchange_weak
- 역시 std::atomic 클래스의 멤버 함수로, compare_exchange_strong과 유사한 작업을 수행합니다. 다만 약간의 차이가 있습니다.
- compare_exchange_weak는 교환을 시도했을 때 실패했을 경우 재시도 여부를 지정하는 데 사용됩니다.
- 실패 시 재시도할 수 있는데, 이때 compare_exchange_weak는 반환 값으로 성공 여부를 나타내는 불린 값을 주지만, 실패 시에 다시 시도하기 위해 사용됩니다.
이 두 함수는 주로 다중 스레드 환경에서 공유되는 변수나 자원을 안전하게 업데이트하고 조작하기 위해 사용됩니다. 선택할 때 compare_exchange_weak는 실패 시 재시도할 수 있는 기능이 있지만, 이때 재시도할 확률이 높아지기 때문에 특히 루프를 사용하는 경우에 유용합니다. 반면 compare_exchange_strong은 명확한 성공 여부를 반환하기 때문에, 교환에 성공했을 때의 작업을 보다 안정적으로 수행할 수 있습니다.
LockFree 개념에도 쓰임
Mutex와 CAS
뮤텍스(Mutex)와 CAS(Compare-And-Swap)는 모두 다중 스레드 환경에서의 동기화를 위해 사용되는 기법입니다. 하지만 그 동작 원리와 사용 방식에는 차이가 있습니다.
- 뮤텍스(Mutex):
- 뮤텍스는 상호 배제(mutual exclusion)를 위해 사용됩니다. 한 스레드가 공유 자원에 접근하고 있을 때, 다른 스레드들은 대기하고 있어야 합니다. 이 때문에 뮤텍스는 경쟁 조건(race condition)을 방지하고 데이터 무결성을 유지할 수 있습니다.
- 뮤텍스는 lock()과 unlock() 같은 함수를 사용하여 임계 영역(critical section)을 보호합니다. lock() 함수는 다른 스레드가 해당 임계 영역에 들어가지 못하도록 잠금(lock)을 설정하고, unlock() 함수는 잠금을 해제합니다.
- 뮤텍스를 사용하면 동기화를 보장할 수 있지만, 락 경합(lock contention)으로 인한 성능 저하가 발생할 수 있습니다.
- CAS(Compare-And-Swap):
- CAS는 원자적 연산(atomic operation)을 지원하는 하드웨어에서 제공하는 기능입니다. 이 연산은 변수의 현재 값을 비교하고, 주어진 새로운 값으로 업데이트하는 연산을 한 번의 원자적 작업으로 수행합니다.
- CAS는 일반적으로 락 없는(non-blocking) 알고리즘을 구현할 때 사용됩니다. 스레드는 자원에 접근하기 전에 CAS를 사용하여 해당 자원의 상태를 확인하고, 원자적으로 업데이트할 수 있습니다. 이렇게 함으로써 다중 스레드 간의 경쟁 없이 안전하게 자원을 업데이트할 수 있습니다.
- CAS는 락을 사용하지 않기 때문에 락 경합에 의한 성능 저하가 없으며, 따라서 더 높은 동시성과 성능을 제공할 수 있습니다.
따라서 뮤텍스는 락을 사용하여 임계 영역을 보호하고, CAS는 원자적 연산을 통해 락 없는 동기화를 지원합니다. 선택하는 것은 사용하려는 상황과 요구사항에 따라 다릅니다. 동기화가 간단하고 명확한 경우 뮤텍스를 사용할 수 있지만, 락 경합으로 인한 성능 저하가 예상되는 경우나 락 없는 동기화가 필요한 경우 CAS를 고려할 수 있습니다.
슬립락 (Sleeplock)
동작 방식: 슬립락은 락을 획득할 수 없는 경우, 일정 시간 동안 대기한 후에 스레드를 슬립 상태로 전환합니다. 다른 스레드가 락을 해제하면 깨어나서 다시 락을 시도합니다.
특징: 스핀락보다는 대기 시간 동안 CPU를 덜 사용하며, 대기 시간이 길 경우에 유용합니다. 하지만 스레드를 슬립 상태로 변경하고 깨우는 오버헤드가 발생할 수 있습니다.
콘텍스트스위칭이 일어난다 유저모드와 커널모드를 왔다 갔다 함.
#include <thread>
#include <mutex>
class SpinLock {
public:
void lock()
{
bool expected = false;
bool desired = true;
while (_locked.compare_exchange_strong(expected, desired) == false)
{
expected = false;
//this_thread::sleep_for(std::chrono::milliseconds(100));//언제까지 멈춰라
this_thread::sleep_for(0ms);//입력한 시간동안 제 스케줄링되지않는다.
//this_thread::yield();////언제든지 스케줄링될 수 있지만 지금은 필요하지않으니 반환하겠다.
}
}
void unlock()
{
_locked.store(false);
}
private:
atomic<bool> _locked = false;
};
int32 sum = 0;
mutex m;
SpinLock spinLock;
void Add() {
for (int32 i = 0; i < 10'0000; i++)
{
lock_guard<SpinLock> gard(spinLock);
sum++;
}
}
void Sub() {
for (int32 i = 0; i < 10'0000; i++)
{
lock_guard<SpinLock> gard(spinLock);
sum--;
}
}
int main()
{
std::thread t1(Add);
std::thread t2(Sub);
t1.join();
t2.join();
cout << sum << endl;
}이벤트락 (AutoResetEvent와 ManualResetEvent)
정말 가끔씩 혹은 오랫동안 작업이 진행될 때 SpinLock을 사용하면 지속적으로 가능한지 유무를 판단하기 때문에 CPU가 불필요하게 사용될 수도 있다. 이때 EvnetLock을 사용하여 스레드가 대기상태에 있다가 락이 사용됐는지를 판단하여 한번만 실행하게 변경하여 cpu의 사용량을 줄일 수 있다. 하지만 커널모드로 들어가서 작업을 처리하기 때문에 활용성은 좋지만( 프로그램 간 데이터를 동기화 ) 커널까지 가기 때문에 비용이 많이 들어 빈번하게 일어나는 작업에서는 Spinlock보다 좋지 않을 수 있다.
이벤트락에서는 AutoResetEvent와 ManualResetEvent가 존재한다.(c#기준)
C++에서는 CreateEvent를 사용하며 커널 오브젝트라고 불린다. 커널 오브젝트를 사용한다면 다른 프로그램 간 데이터를 동기화할 수도 있다는 장점이 있다. 옛날방식
CreateEvent사용을 위한 주요 키워드.
CreateEven(보안속성, ManualReset, bInitialState, ipname)
- bInitialState을 사용하여 C++에서는 AutoResetEvent와 ManualResetEvent로 구분할 수 있다.
- False시 AutoResetEvent, True시 ManualResetEvent
- bInitialState는 event의 초기 상태값으로 false는 사용 안 한 상태로 thread가 대기상태로 변경되며 True는 그 반대이다.
SetEvent
- 시그널 상태를 true로 변경되며 이때 thread는 대기상태에서 실행으로 변경된다.
ResetEvent
- 시그널 상태를 false로 변경하며 이때 thread는 대기한다.
WaitForSingleObject는
- thread가 대기하는 장소이며 시그널 상태에 따라 실행하거나 대기한다.
#include <thread>
#include <mutex>
#include <windows.h>
mutex m;
queue<int32> q;
HANDLE handle;
void Producer()
{
while (true)
{
{
unique_lock<mutex> lock(m);
q.push(100);
}
::SetEvent(handle);//시그널 상태로 변경 bool = true;
this_thread::sleep_for(10000ms);//오랜기간 한번씩 실행된다는 가정.
}
}
void Consumer() {
while (true)
{
//해당장소에서 대기. SetEvent로 시그널 상태가 true가되면 다시 실행
::WaitForSingleObject(handle, INFINITE);
//CreateEvent에서 ManualReset상태를 true로 설정한 경우 ResetEvent를 통해 수동으로 시그널상태값 false로 조정해줘야함.
//::ResetEvent(handle);
unique_lock<mutex> lock(m);
if (q.empty() == false)
{
int32 data = q.front();
q.pop();
cout << data << endl;
}
}
}
int main()
{
//커널 오브젝트 : 커널에서 처리해주는 이벤트
//Usage Count -
//Signal / Non-Signal - 켜져있거나 꺼져있음을 정의하는 bool
// Auto/Manual - 자동, 수동 정의
handle = ::CreateEvent(NULL/*보안속성*/, FALSE/*ManualReset*/, FALSE/*bInitialState*/, NULL );
std::thread t1(Producer);
std::thread t2(Consumer);
t1.join();
t2.join();
::CloseHandle(handle);
}이벤트락과 조건 변수락 컨디션 베리어블(Condition Variables)
위에 설명한 이벤트방식보다 더 나은 방법이다.
Condition Variables는 이벤트락과 동작 방식이 비슷하지만 커널오브젝트가 아닌 UserLevel오브젝트에서 동작하며 변화에 있어 락을 체크하기 위한 조건을 부여할 수 있다.
또 한 스레딩과 동시성 프로그래밍에서 사용되는 동기화 기법 중 하나로, 여러 스레드 간에 특정 조건이 충족될 때까지 대기하거나, 다른 스레드에게 신호를 보내고 깨울 때 사용됩니다. 주로 Producer-Consumer(가짜 기상으로 이벤트를 받아 처리하로 가는 찰나의 순간에 다른 스레드로 인해 데이터가 변경되는) 문제나 다른 협력적인 스레드 간 통신 시에 활용됩니다.
C++에서는 condition_variable를 사용한다.
condition_variable 사용을 위한 주요 키워드.
notify_one(보안속성, ManualReset, bInitialState, ipname)
- wait중인 스레드가 있으면 딱 1개만 깨운다.
Wait
- Lock을 잡으려고 시도 후 조건 확인 - 만족하지 않는다면 lock을 풀어주고 대기상태로 진입한다.
#include <mutex>
mutex m;
queue<int32> q;
//UserLevel Object(커널오브젝트x)
condition_variable cv;
void Producer()
{
while (true)
{
//1) Lock을 잡고
//2) 공유 변수 값을 수정
//3) Lock풀고
//4) 조건변수 통해 다른 쓰레드에게 통지
{
unique_lock<mutex> lock(m);
q.push(100);
}
cv.notify_one();//wait중인 쓰레드가 있으면 딱 1개만 깨운다.
}
}
void Consumer() {
while (true)
{
unique_lock<mutex> lock(m);
cv.wait(lock, []() {return q.empty() == false; });//깨어나는 조건
//1) Lock을 잡으려고 시도
//2) 조건 확인 - 만족하지 않는다면 lock을 풀어주고 대기상태로 진입한다.
int32 data = q.front();
q.pop();
cout << data << endl;
}
}
int main()
{
std::thread t1(Producer);
std::thread t2(Consumer);
t1.join();
t2.join();
}비동기방식 future
비동기방식이란 반드시 멀티스레드가 아닐 수 도있다. 단순히 현재실행하지 않고 나중에 결과물이 나올 수 있다는 의미도 가능하다.
비동기(Asynchronous)"란 어떤 작업이 순차적으로 진행되지 않고, 다른 작업과 동시에 실행될 수 있는 방식을 의미합니다. 비동기적 프로그래밍은 일반적으로 두 가지 작업이 동시에 진행되거나, 한 작업이 다른 작업을 기다리는 동안 블로킹되지 않는 방식으로 이루어집니다.
비동기적 작업은 다음과 같은 특징을 가집니다:
- 병렬성 (Concurrency): 여러 작업이 동시에 진행될 수 있습니다. 이는 CPU 코어의 개수에 맞게 작업을 분산하여 성능을 향상할 수 있습니다.
- 논블로킹 (Non-blocking): 비동기적 작업은 한 작업이 다른 작업을 기다리는 동안 블로킹되지 않습니다. 대신, 작업이 완료될 때까지 기다리는 대신, 다른 작업을 수행하거나, 작업이 완료될 때까지 대기하지 않고 다음 코드를 실행할 수 있습니다.
- 이벤트 기반 (Event-driven): 비동기적 프로그래밍은 종종 이벤트 기반으로 이루어집니다. 특정 이벤트가 발생하면 그에 따라 특정 작업이 실행되도록 설계됩니다.
- Callback 함수: 비동기적 작업은 종종 콜백(callback) 함수를 사용하여 작업이 완료되면 호출되는 방식으로 구현됩니다.
스레드보다 가벼운 비동기 방식인 future가 있다. 일회성으로 사용할 목적으로 성능이 우수하다. (c#에 async) 비동기적인 방식은 작업이 완료되기를 기다리지 않고, 작업이 진행되는 동안 다른 작업을 수행할 수 있는 방식을 의미한다. future는 thread pool에서 관리되어 효율적이다.
thread pool이란
프로그램이 생성하는 스레드의 수를 제한하고, 작업이 완료되면 해당 스레드를 풀에 반환하여 재사용한다. 이를 통해 스레드 생성 및 소멸의 오버헤드를 줄이고, 시스템 자원을 효율적으로 사용할 수 있다.
#include <future>
int64 Calculate() {
int64 sum = 0;
for (int32 i = 0; i < 1000000'000; i++)
sum += i;
return sum;
}
void PromiseWorker(std::promise<string>&& promise) {
promise.set_value("secret Message");
}
void TaskWorer(std::packaged_task<int64(void)>&& task){
task();
}
int main()
{
//std::future
{
//1) deferred -> 선언 후 나중에 실행(지연실행) 멀티스레드 환경은아님
//2) async -> 별도의 스레드를 만들어서 실행
//3) deferred | async -> 둘 중 알아서 골라서 실행
std::future<int64> future = std::async(std::launch::async, Calculate);
////다른일 실행
std::future_status stauts = future.wait_for(1ms);//현재 비동기 상태
if (stauts == future_status::ready)//비동기 종료됐는지
{
}
int64 sum = future.get();//결과가 필요한 시점
}
//std::promise - 다른스레드에게 소유권을 이임해준다. 반환을 얻기위해 전역변수를 쓰지 않아도된다.
{
//미래(std::future)에 결과물을 반환해줄꺼라 약속(std::promise)
std::promise<string> promise;
std::future<string> future = promise.get_future();
thread t(PromiseWorker, std::move(promise));
string message = future.get();
t.join();
}
//std::packaged_task
{
std::packaged_task<int64(void)> task(Calculate);// 다른쪽 스레드에서 호출할것 임을 명시
std::future<int64> future = task.get_future();
std::thread t(TaskWorer, std::move(task));
int64 sum = future.get();
t.join();
}
}TLS(Thread Local Storage)
Thread Local Storage (TLS)는 각 스레드가 독립적으로 사용하는 스레드별 데이터 저장 영역을 가리킵니다. 이것은 스레드 간에 데이터를 공유하지 않고, 각 스레드가 독자적으로 접근 가능한 저장 공간을 제공합니다.
TLS는 다중 스레드 환경에서 각 스레드가 자체적으로 유지해야 하는 데이터나 상태를 저장하는 데 유용합니다. 각 스레드는 자신의 TLS에 데이터를 저장하고 필요할 때마다 접근할 수 있으며, 이는 동일한 프로세스 내에서 여러 스레드가 동시에 실행될 때 유용합니다.
스레드 로컬 스토리지는 전역 변수와는 달리, 각 스레드가 고유한 인스턴스를 갖습니다. 따라서 한 스레드에서 TLS에 저장된 데이터는 다른 스레드에서 직접적으로 접근할 수 없습니다. 이러한 특성은 다중 스레드 환경에서 데이터 공유와 관련된 문제를 방지하고 스레드 간에 데이터 충돌을 방지하는 데 도움이 됩니다.
주로 프로그래밍 언어나 환경에서 TLS는 스레드별로 로컬 변수를 생성하고 유지하기 위해 사용됩니다. 이는 각 스레드가 독립적으로 작업을 수행하면서 자신만의 데이터를 보유하고 관리할 수 있도록 해줍니다.
#include <thread>
thread_local int32 LThreadId = 0;
void ThreadMain(int32 threadId) {
LThreadId = threadId;
while (true)
{
cout << LThreadId << endl;
this_thread::sleep_for(1s);
}
}
int main()
{
vector<thread> threads;
for (int32 i = 0; i < 10; i++)
{
int32 threadId = i + 1;
threads.push_back(thread(ThreadMain, threadId));
}
for (thread& t: threads)
{
t.join();
}
}LockStack 구현
이렇게 직접 LockStack을 구현하면 혹시 모를 데드락 현상을 조금이나마 줄일 수 있다.
#pragma once
#include<mutex>
template<typename T>
class LockStack
{
public:
LockStack() { }
LockStack(const LockStack&) = delete;//복사연산 금지
LockStack& operator=(const LockStack&) = delete;//복사대입연산 금지
void Push(T value) {
lock_guard<mutex> lock(_mutex);
_stack.push(std::move(value));//값을 복사하는게 아닌 이동을 통해 성능향상.
_condVar.notify_one();
}
bool TryPop(T& value)
{
lock_guard<mutex> lock(_mutex);
if (_stack.empty())
return false;
value = std::move(_stack.top());
_stack.pop();
return true;
}
void WaitPop(T& value) {
unique_lock<mutex> lock(_mutex);
_condVar.wait(lock, [this] {return _stack.empty() == false; });
value = std::move(_stack.top());
_stack.pop();
return true;
}
private:
stack<T> _stack;
mutex _mutex;
condition_variable _condVar;
};LockFreeStack 구현
- ock-Free Stack은 락 없이 동기화를 구현하는 스택입니다. 즉, 다중 스레드가 동시에 스택에 접근해도 락을 사용하지 않습니다.
- Lock-Free Stack은 원자적 연산과 CAS(Compare-And-Swap) 같은 동기화 기법을 사용하여 상태를 변경하고 관리합니다.
- 이러한 방식으로 락을 사용하지 않기 때문에 스레드 간 경합 없이 동시에 여러 스레드가 스택에 접근할 수 있습니다. 따라서 Lock-Free Stack은 락을 사용하는 방식보다 더 높은 동시성을 제공하고, 락 경합으로 인한 성능 저하가 없습니다.
LockStack은 락을 사용하여 동기화를 구현하므로 단순하지만 성능이 떨어질 수 있습니다. 반면에 Lock-Free Stack은 락을 사용하지 않기 때문에 더 높은 동시성을 제공하며 성능이 향상될 수 있습니다.
template<typename T>
class LockFreeStack
{
struct Node
{
Node(const T& value) : data(value), next(nullptr)
{
}
public:
T data;
Node* next;
};
public:
//1) 새로운 노드를 만든다.
//2) 새로운 노드 = head
//3) head = 새로운 노드
void Push(const T& value) {
Node* node = new Node(value);
node->next = _head;
//풀어쓴 compare_exchang_week
//if (_head == node->next)
//{
// _head = node;
// return true;
//}
//else {
// node->next = _head;
// return false;
//}
while (_head.compare_exchange_weak(node->next, node) == false)
{
//node->next = _head;
}
//_head = node;
}
//1) head 읽기
//2) head->next 읽기
//3) head = head-> next
//4) data 추출해서 반환
//5) 추출한 노드 삭제
bool TryPop(T& value)
{
++_popCount;
Node* oldHead = _head;
/*풀어쓴 compare_exchang_weak
if (_head == oldhead) {
_head = oldHead->next
}
else {
oldHead->next = oldHead;
}*/
while (oldHead && _head.compare_exchange_weak(oldHead, oldHead->next) == false)
{
}
if (oldHead == nullptr)
{
--_popCount;
return false;
}
value = oldHead->data;
TryDelete(oldHead);
//delete oldHead;
return true;
}
void TryDelete(Node* oldHead) {
//실행중인 쓰레드가 하나인지 확인
if (_popCount == 1)
{
Node* node = _pendingList.exchange(nullptr);
if (--_popCount == 0)
{
DeleteNodes(node);;
}
else if(node)
{
ChainPendingNodeList(node);
}
delete oldHead;
}
else
{
ChainPendingNodeList(oldHead);
_popCount;
}
}
void ChainPendingNodeList(Node* first, Node* last)
{
last->next = _pendingList;
while (_pendingList.compare_exchange_weak(last->next, first) == false)
{
}
}
void ChainPendingNodeList(Node* node)
{
Node* last = node;
while (last->next)
last = last->next;
ChainPendingNodeList(node, last);
}
void ChainPendingNode(Node* node) {
ChainPendingNodeList(node, node);
}
static void DeleteNodes(Node* node)
{
while (node)
{
Node* next = node->next;
delete node;
node = next;
}
}
private:
atomic<Node*> _head;
atomic<uint32> _popCount = 0;//pop을 실행중인 쓰레드 개수
atomic<Node*> _pendingList; // 삭제되어야할 노드들 (첫번쨰 노드)
};'VisualStudio > C++서버' 카테고리의 다른 글
| [C++] Select 모델과 WASEventSelect모델 (1) | 2024.05.23 |
|---|---|
| [C++] setsockopt와 Socket 설정 (0) | 2024.05.23 |
| [C++] 블로킹방식 TCP/IP 소스 (0) | 2024.05.23 |
| [C++] 빌드폴더 위치변경 방법 & pch사용 세팅 방법 & lib 참조 방법 (0) | 2023.11.22 |
| [C#서버][개념] 임계영역과 데드락 해결방법 (0) | 2022.10.26 |