사용할 모델은 야놀자의 eeve 모델을 사용하여 진행함
HuggingFace Hub 설치
pip install huggingface-hub
모델 다운로드
https://huggingface.co/heegyu/EEVE-Korean-Instruct-10.8B-v1.0-GGUF
heegyu/EEVE-Korean-Instruct-10.8B-v1.0-GGUF · Hugging Face
Usage requirements # GPU model CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install llama-cpp-python --force-reinstall --upgrade --no-cache-dir --verbose # CPU CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install llama-cpp-python --force-reinstall
huggingface.co
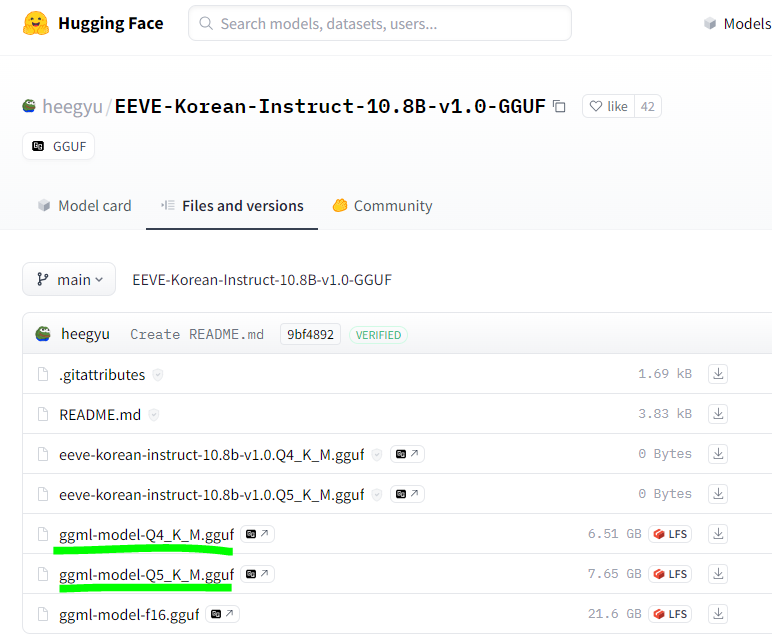
아래경로에서 둘 중 하나를 다운로드한다.
cmd로 다운 받는 방법
huggingface-cli download \
허깅페이스 주소 \
ggml-model-Q5_K_M.gguf \
--local-dir 본인의_컴퓨터_다운로드폴더_경로 \
--local-dir-use-symlinks False다운로드한 gguf파일은 모델파일로 변경
다운로드한 gguf파일과 같은 경로에 Modelfile를 만들고 아래의 소스코드를 넣는다.
FROM ggml-model-Q5_K_M.gguf
TEMPLATE """{{- if .System }}
<s>{{ .System }}</s>
{{- end }}
<s>Human:
{{ .Prompt }}</s>
<s>Assistant:
"""
SYSTEM """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions."""
PARAMETER stop <s>
PARAMETER stop </s>Ollama에 모델 올리기
cmd경로 모델저장 폴더 앞경로에서 해당 명령어를 입력한다.
- ollama create - 올라마에 모델을 올리겠다는 명령어
- EEVE-Korean-10.8B - 모델명설정
- -f EEVE-Korean-Instruct-10.8B-v1.0-GGUF - 폴더 경로
- Modelfile - 앞서 만든 modefile
ollama create EEVE-Korean-10.8B -f EEVE-Korean-Instruct-10.8B-v1.0-GGUF/Modelfile
cmd에서 ollama 모델 실행 및 사용
ollama run EEVE-Korean-10.8B:latest
모델 불러오기
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain_core.callbacks.manager import CallbackManager
llm = ChatOllama(
model="EEVE-Korean-10.8B:latest",
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
)임베딩 모델설정(jhgan/ko-sroberta-multitask모델사용)
from langchain.embeddings import HuggingFaceEmbeddings
model_name = "jhgan/ko-sroberta-multitask"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
embedding_model = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader, TextLoader, Docx2txtLoader
def load_and_split_documents(loaders):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=100)
all_splits = []
for loader in loaders:
pages = loader.load_and_split()
splits = text_splitter.split_documents(pages)
all_splits.extend(splits)
return all_splits
loaders = [
PyPDFLoader('pdf파일 경로설정'),
TextLoader('txt파일 경로설정', encoding='UTF8')
]
all_splits = load_and_split_documents(loaders)백터 DB 및 레트리버 생성
from langchain.vectorstores import Chroma
vector = Chroma.from_documents(documents=all_splits, embedding=embedding_model)
retriever = vector.as_retriever()Prompt설정 및 RAG
첫 번 째r retriever에서는 memory에 저장된 사용자의 질문과 ai질문을 이용하여 답변을 생성한다.
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# ### 질문에 대한 정의 ###
contextualize_q_system_prompt = """Given a chat history and the latest user question \
which might reference context in the chat history, formulate a standalone question \
which can be understood without the chat history. Do NOT answer the question, \
just reformulate it if needed and otherwise return it as is. \
Always in Korean."""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)두 번째 retriever에서는 첫 번 째 retriever에서 만든 내용과 사용자의 질문을 이용하여 출력 결과를 얻는다.
# ### 질문에 대한 대답 ###
qa_system_prompt = """You are an assistant for question-answering tasks. \
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
Use three sentences maximum and keep the answer concise.\
Always answer in Korean.\
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)사용자 질문 및 AI 답변 Memory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
#모든 세션정보 딕셔너리로 관리 key에는 sessionid, value에는 모든 히스토리 존재
GHistorys = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in GHistorys:
GHistorys[session_id] = ChatMessageHistory()
return GHistorys[session_id]
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)사용
sessionQu = conversational_rag_chain.invoke(
{"input": "질문 쓰는 곳"},
config={
"configurable": {"session_id": "어떤 사용자인지 아이디 값 부여"}
},
)
참고
https://python.langchain.com/v0.1/docs/expression_language/how_to/message_history/
Add message history (memory) | 🦜️🔗 LangChain
The RunnableWithMessageHistory lets us add message history to certain types of chains. It wraps another Runnable and manages the chat message history for it.
python.langchain.com
https://python.langchain.com/v0.1/docs/use_cases/question_answering/chat_history/
Add chat history | 🦜️🔗 LangChain
In many Q&A applications we want to allow the user to have a back-and-forth conversation, meaning the application needs some sort of "memory" of past questions and answers, and some logic for incorporating those into its current thinking.
python.langchain.com
https://www.youtube.com/watch?v=VkcaigvTrug
'AI' 카테고리의 다른 글
| [AI] 대형 언어 모델 파인튜닝 기법 정리 (SFT, PEFT, RLHF, DPO, RL) (1) | 2025.03.26 |
|---|---|
| [AI] LoRA 기반 PEFT 파인튜닝과 용어정리 (3) | 2025.02.27 |
| [AI] Ollama 다운로드 및 모델 다운 방법 (1) | 2024.06.27 |
| [AI] 임베딩(Embedding) (0) | 2024.05.09 |
| [AI] AI 용어정리 (0) | 2024.05.08 |